Replication means keeping multiple copies of the same data on different servers. There are several reasons as to why replication is necessary -
- To keep data geographically closer to the end users. (reduce latency)
- To allow the system to continue working even if parts of it fails. (increase availability)
- To scale out the number of servers that can serve read queries (increase read throughput)
If the data to be replicated does not change frequently, then replication is quite easy. The difficulty in replication lies in handling changes to replicated data. There are three popular architectures for replicating changes between nodes - single-leader, multi-leader and leaderless replication. Almost all distributed databases use one of these three approaches.
- Single-Leader (Master-Slave) -> Mongo DB, PostgreSQL, MySQL
- Multi-Leader (Multi-Master) -> Dynamo DB
- Leaderless (Masterless) -> Scylla DB
Synchronous vs Asynchronous Replication
An important detail of a replicated system is whether the replication happens synchronously or asynchronously. In relational databases this is often a configurable option; other systems are often hardcoded to be either one or the other.
- Synchronous Replication - the leader node waits for the updated data to be successfully replicated to the follower nodes, before responding to the client. If there are more than one followers in the setup, the leader can propagate the write operation sequentially or parallelly. Still, in either case, it will continue to wait until it gets a confirmation, which will continue to keep the client blocked. Thus having a large number of followers means a longer block for the client, affecting its throughput. Synchronous Replication ensures that the followers are always in sync and consistent with the leader; hence, this setup is fault-tolerant by default. Even if the leader crashes, the entire data is still available on the followers, so the system can easily promote any one of the followers as the new leader and continue to function as usual. A major disadvantage of this strategy is that the client and the leader can remain blocked if a follower becomes non-responsive due to a crash or network partition. Due to the strong consistency check, the leader will continue to block all the writes until the affected follower(s) become available again, thus bringing the entire system to a halt.

- Asynchronous Replication - once the leader updates its own copy of the data, it immediately completes the operation by responding to the client. It does not wait for the changes to be propagated to the followers, thus minimizing the block for the client and maximizing the throughput. The leader, after responding to the client, asynchronously propagates the changes to the followers, allowing them to catch up eventually. This replication strategy is most common and is the default configuration of most distributed data stores out there. One major disadvantage of having a fully asynchronous system is the possibility of data loss. What if the write happened on the leader node, and it crashed before the changes could propagate to any of the followers. The changes in data that are not propagated are lost permanently, defeating durability.

Weakening durability may sound like a bad trade-off, but asynchronous replication is nevertheless widely used, especially if there are many followers or if they are geographically distributed.
Due to the obvious disadvantages in the synchronous replication approach, it is impractical for all the followers to be synchronous. In practice, a Semi-Synchronous Replication system is used, where maybe one or two followers are synchronous while the rest of them are asynchronous. If the synchronous follower crashes or becomes unavailable, one of the asynchronous followers is made synchronous.

Single Leader Architecture
Each node that stores a copy of the database is called a replica or follower. Every write to the database, needs to be processed by every replica. The most common solution for this is to designate one of the replicas as the leader.
The leader accepts write requests, writes the updated data to its database, and then propagates the data change to all the followers (other replicas) as part of a replication log or a change stream. Each follower take the log from the leader and updates its local copy of the database accordingly, by applying all writes in the same order as they were processed on the leader node.
Only the leader can accept and execute write requests. However, read requests can be accepted and executed by both the leader nodes and the follower nodes.

Scalability
There is often the need to add more follower nodes - either to replace failed nodes or to increase the number of replicas in order to scale. The new follower must have an accurate copy of the leader's data - data needs to be copied from either the leader or some other up-to-date follower.
Simply copying data from one node to the new follower node is generally not a good idea since clients are constantly sending write requests to the database and the data is in a constant state of flux. So, a standard copy would fetch different data at different points in time, leading to an inconsistent or bad data copy in the follower node.
One could also consider locking mechanisms - by locking the database (making it unavailable for writes), but that would go against the high availability goal. Fortunately, it is possible to setup a new follower node without any downtime,
- Capture a snapshot of the leader database
- Copy the snapshot to the new follower node
- The follower connects to the leader and requests all the data changes that have happened since the snapshot was taken
- When the follower has processed with backlog of data changes, it is now up-to-date and is ready to serve read requests from clients and can continue to process data changes from leader as they happen.
Availability & Fault Tolerance
Any node in the system can go down unexpectedly, either due to a fault or maybe due to some maintenance work. The goal here is to keep the system as a whole running despite individual node failures.
Follower Failure
The follower maintains a log of all the changes it has received from the leader in the local disk. If the follower crashes or the connection between the follower and the leader is temporarily lost, it can recover quite easily using the log.
The follower can get the last transaction that occurred before the crash from the log and can connect to the leader and request all the additional transactions carried out during it's downtime.
Leader Failure
Handling a leader failure is a bit trickier - one of the followers need to be promoted to the leader, the client write requests need to be re-routed to the new leader, and the other followers need to start consuming data changes from the new leader. This process is called failover.
The best candidate for leadership is usually the replica with the most up-to-date data changes from the old leader (to minimize any data loss). If the old leader comes back, the system needs to ensure that the old leader becomes a follower. In certain fault scenarios, it can happen that two nodes both believe they are the leader. This situation is called split brain. In such a situation, both leaders accept writes, resulting data conflicts. The is no process to resolve such conflicts - data is likely to be corrupted or lost.
Replication Methods
There are multiple replication methods which are used in a leader based replication system, and all of them involve some sort of replication logs. Replication logs are a key part of leader-based replication, a method of keeping multiple copies of a database in sync. The leader node is responsible for writing all changes to the database, and the follower nodes replicate those changes from the leader.
Statement Based Replication
Statement based replication is the most simplest replication method, but also the most limited one. Here, the leader logs every write statement that it executes and sends it to its followers. The followers then execute the statements in the same order as their leader.
Some major pain points in this kind of replication -
- Non-deterministic functions such as
NOW()orRAND()is likely to generate a different value in each replica - Maintaining and executing the proper sequence of statements in a highly concurrent system is a problem.
- Statements which have side effects (e.g. triggers or user defined functions) may result in different side effects on different replicas.
It is possible to work around the above issues, by making all statements as deterministic as possible, but there are so many edge cases that other methods are now preferred.
Write Ahead Logs
Write ahead log (WAL) is an append-only sequence of bytes containing all changes to the database.
The same log can be used to build a replica on another node. Other than storing the log in local disk, the leader also sends this log to its followers. The followers process the log and builds a copy of the exact same data structure as found on the leader
PostgreSQL and Oracle uses this method of replication, among others. The primary disadvantage of this method is that the logs are closely coupled to the storage engine internals. As a result, it is typically not possible to run different versions of the database software on different nodes.
Row Based (Logical) Replication
An alternative is to use different log formats for replication and for storage internals. This allows the replication log to be separate and decoupled from the storage system internals. This kind of replication log is called logical log. The log records contain enough information to identify the row that was changed and the new values of all columns in the row. The leader then sends the log record to the followers, and the followers apply the change to their databases.
A transaction that modifies multiple rows generates several log records, followed by a record indicating that the transaction was committed. MySQL's binlog when configured for row-based replication, uses this method.
Logical (row-based) log replication is a good choice for databases that need to be flexible and scalable. It is also a good choice for databases that need to be upgraded frequently, because the leader and the followers can be running different versions of the software.
Trigger Based Replication
Trigger-based replication is a more complex type of replication, but it is also the most flexible. All the previous methods of replication are implemented by the database system, without involving any application code. Sometimes, more flexibility is needed, for example, if a subset of data needs to be replicated or data needs to be replicated between different kinds of databases and so on.
In trigger-based replication, the leader uses database triggers to log data changes into a separate table. An external process then reads the data changes from the table and replicates them to another system.
Trigger-based replication is a good choice for databases that need to be customized or integrated with other systems. However, it can be more difficult to implement and maintain than other types of replication.
The best type of replication log depends on specific needs. If the need is a simple and reliable replication solution, then WAL shipping is a good choice. If a more flexible solution is needed, then logical (row-based) log replication is a good choice. If customizing the replication process or integrating with other systems is a requirement, then trigger-based replication may be the best option.
Replication Lag
Leader based replication architecture is ideal for read heavy systems. For workloads that consist of mostly reads and only a small percentage of writes, this is an attractive option. In this read-scaling architecture, one can increase the capacity for serving read requests by simply increasing the number of followers. However, this approach realistically works only for asynchronous replication - if the system tries to synchronously replicate to all followers, then a single node failure or network outage would make the entire system unavailable.
Unfortunately, if an application reads from an asynchronous follower, if may read outdated information if the follower has fallen behind. This leads to apparent inconsistencies, though temporary, in the database. This effect is known as eventual consistency. Normally, the delay between a write happening on the leader and being reflected on the follower is know as replication lag.
Read after Write consistency - To fix replication lag, read-after consistency should be employed. Sometimes, this is referred to as read-your-writes-consistency. This offers a guarantee that if a user makes an update, they will see the updates when they view the information. This reassures the user that their input has been saved correctly even though replication might still be going on in the background.
To implement read-after-write guarantee:
- When reading any new information that the user has updated, read it from the leader. Otherwise, read it from the follower. This is ideal for cases such as profile information that can only be editable by the owner of the profile.
- The client keeps track of the timestamp for the most recent write. The system ensures that the replica serving any reads for that user has the updates until that timestamp.
- Monitor the replication lag on followers and prevent queries on any followers or replicas that are more than one or two minutes behind the leader.
- Databases such as MongoDB and Object Storage(such as S3) have started providing read-after-write as an option.
Multi-Leader Architecture
Leader based replication has one major downside - there is only one leader, hence all writes must go through it. Database writes are blocked if the client fails to connect to the leader or if the leader goes down.
A natural extension is to allow multiple leaders to accept write requests. Replication still happens the same way - each node that processes writes must forward the data changes to all other nodes.

Generally, multi-leader architecture is more performant in terms of handling write requests and also more fault tolerant than single leader architecture. Even if one leader node goes down due to some fault or network outage, other leaders can still accept write requests.
Conflict Resolution
The biggest concern with multi-leader replication is that write conflicts can occur and conflict resolution is required. When a value is changed on local leader and that leader tries to sync-it with other local leaders, it has to resolve any conflicts in the value in order to reach a consistent state. In a typical single leader replication concurrent writes to a resource can be avoided by following approaches:
- Queuing write requests so that only a single request is able to change the resource.
- Returning errors for write requests if the resource is currently locked by another request
The above solutions don’t seem to work in a multi-leader system. There are custom approaches that are required for conflict resolution that are needed for multi-leader replication.
Avoid Conflicts
If the client or application can ensure that all the write requests for a particular data record goes through the same leader node, then merge conflicts can be simply avoided. Of course, this is not very full-proof since in the event of leader node failure, the client will have to re-route all write requests to another leader node, ultimately leading to possible conflicts.
Converging Towards Consistent State
In single leader replication, all the writes are applied in sequential order, but there is no defined ordering of writes in multi-leader replication. If each replica simply starts committing write requests without considering the intended orders, the system would soon end up with an inconsistent state i.e. different replicas having different versions of the data. Generally, merge conflicts can be resolved by -
- Assigning unique IDs to each write request, like timestamp, long random number or UUID. The write request with the highest ID will be considered and others will be discarded. For example, if timestamp is used as the unique ID then this technique is known as last write wins (LWW).
- Assign unique IDs to each replica node, and only the write request from the replica with the highest ID will be considered. Although this approach removes the dependency of syncing timestamps, but there is still possibility of data loss.
- Record all updates and let user handle merge conflict resolution. Similar to how version control systems like Github or Bitbucket inform users about merge conflicts.
Leaderless Architecture
There is another style of replication that databases follow in which update operation is not bounded by a leader node known as leaderless replication. Databases implementing this replication are also famously known as Dynamo-style databases as this was initially implemented in production by DynamoDB followed by other open source projects such as CassandraDB.
In this implementation client sends writes to several replicas. Some implementations also position a coordinator node that performs this operation on behalf of the client so that client only needs to talk to coordinator node. Note that coordinator node is an abstraction over sending the request to multiple replicas and has no input in the ordering of operations being processed.
Handling Node Failures
Consider there are three replica nodes and one of them goes down due to some failure. A client makes a write request to update a data record - only two out of the three replicas are able to process that request. Now, another client makes a read request of the same data record from the faulty replica. Depending on whether the replica node has recovered or not, it will either return an error or some outdated piece of information.
To solve this problem, when a client reads from the database, it doesn't just send its request to one replica - read requests are also sent to several replicas parallely. The client may receive different data from different nodes - version numbers are used to determine which value is newer.
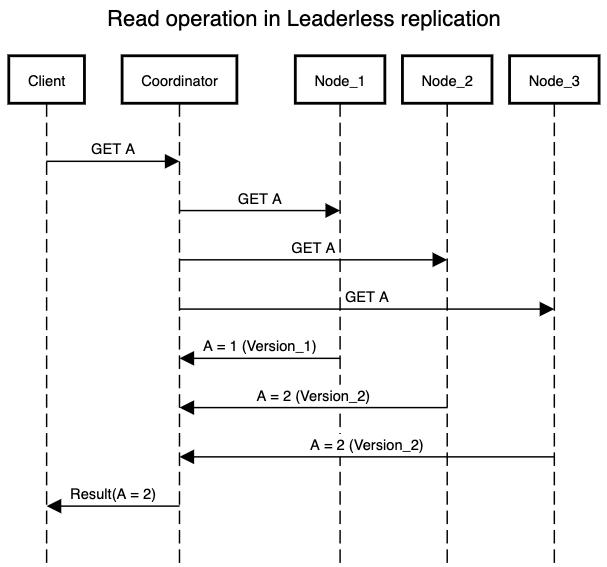
Data Consistency
The end goal in any data storage system is to ensure that all the replica nodes have an updated copy of the data. This can be ensured by following methods -
- Read repair: During a read request, after the client decides on the most updated value it can easily figure out which replicas are out of sync. So it can write back to those replicas with the most updated value.
- Anti-entropy process: Background jobs can look for differences in data stored among the replica nodes and update any missing data. This process is similar to balancing two ledger books and ensuring they look the same after the balancing is finished.
Both the above approaches have their respective advantages and disadvantages. With the read repair system, the out of sync replica is immediately updated with the most recent value. Though it will work only for values that are frequently read. Anti-entropy solves this problem as it looks at the total difference in data and not only the values that are read, but it comes with significant delay as the difference’s among the replicas can be high in volume and hence time taken to sync-up two nodes can increase.
Quorum
The aim is to reduce the number of out-of-sync replicas so that data consistency, performance & latency can be maintained across the database system. For leaderless replication, the following two metrics are important -
- The minimum number of replicas that needs to process a read request for it to be considered a successful read
- The minimum number of replicas that needs to process a write request for it to be considered a successful write
Consider a system where -
N– Total number of nodes in our systemW– Minimum number of nodes required for a successful write operationR– Minimum number of nodes required for a successful read operation
The quorum enforces a constraint on the system using the above three variables using a simple formula. So to introduce the concept of Quorum, for an N node system, a write operation can be determined as successful if it is confirmed by at least
W replicas and read operation as successful if it is confirmed by at least R replicas. Another important property required for a successful quorum is:In dynamo-style databases, the values of
R, N and W are configurable. A common choice is to set N as an odd number and R = W = (N + 1) / 2. However, the numbers can be varied as per requirements. For example, a read heavy system with strong consistency requirements, can set W = N & R = 1. So read requests will be processed quickly and the results will be consistent as the data is always synced across on all N nodes. But the writes will be blocked by failure of even a single node. Whereas for a write heavy system, set W = 1, but doing so we end up in a scenario of data loss if a node goes down and the resource has not yet been replicated to any other node.The quorum
R + W > N, allows the system to tolerate unavailable nodes as follows -- If
W < N, the system can still process writes if a few nodes are unavailable - If
R < N, the system can still process reads if a few nodes are unavailable
For example,
- With
N = 3&W = R = 2, the system can tolerate one unavailable node at a time - With
N = 5&W = R = 3, the system can tolerate two unavailable nodes at a time
Note
- Increasing the value of R & W generally ensures that the system always returns the most updated version of a data record. However, the system becomes less fault tolerant and the availability of the system also suffers.
- Decreasing the value of R & W increases the number of node failures the system can tolerate. This opens up possibilities for making the system highly available. However, the system is more likely to return outdated values for a data record
By satisfying above properties for a quorum, a system can cover majority of scenarios in leaderless replication. Though there are certain edge cases which are hard to tackle if we have strict requirements for consistency.
- Quorums still cannot resolve the issue with concurrent writes or read-writes. If a resource is updated or updated and read from, simultaneously by two clients there is no way to decide which operation happened first.