Document Object Model
The Document Object Model (DOM) is a programming interface for web documents. It connects web pages to programming languages by representing the structure and content of web documents, in memory. The DOM represents a document with a logical tree. Each branch ends in a node, and each node contains objects. DOM allows programatic access to the tree. Nodes can also have event handlers attached to them. Once an event is triggered, the event handlers get executed.
Virtual DOM
However, modifying or making changes to DOM elements is a resource intensive and time consuming process and it involves the browser to revaluate the element’s position, size and other additional properties as well as repaint the screen. This is where Virtual DOM comes into play.
Virtual DOM is basically an in-memory object representation of the actual DOM. Updating a virtual DOM element is much faster and efficient than the actual DOM, as it does not involve any heavy processing like re-painting or recalibrating the web page, and only involves updating the object directly.
Process Overview
During the render process, React starts at the root of the component tree and traverses downward to find all the components that have been flagged as needing updates. For each flagged component, React will call either
FunctionComponent(props) (for functionals components), or ClassComponentInstance.render() (for class components), and save the render outputs for the next steps of the process.A component is generally written in JSX syntax, which is then converted to
React.createElement() calls, which in turn returns equivalent JS objects that describe the intended UI structure. For example, consider the following react component —import React, { useState } from 'react';
function App() {
const [count, setCount] = useState(0);
return (
<div>
<h1>Counter: {count}</h1>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
}
export default App;
Which is then converted into equivalent
createElement() calls —React.createElement(
"div",
null,
[
React.createElement("h1", null, "Counter: 0"),
React.createElement("button", {onClick: setCount() + 1}, "Increment")
]
)
The
createElement calls are responsible for generating the corresponding Virtual DOM representation —{
"type": "div",
"props": {},
"children": [
{
"type": "h1",
"props": {},
"children": [
{
"type": "TEXT_ELEMENT",
"props": {
"nodeValue": "Counter: 0"
}
}
]
},
{
"type": "button",
"props": {
"onClick": "setCount(count + 1)"
},
"children": [
{
"type": "TEXT_ELEMENT",
"props": {
"nodeValue": "Increment"
}
}
]
}
]
}
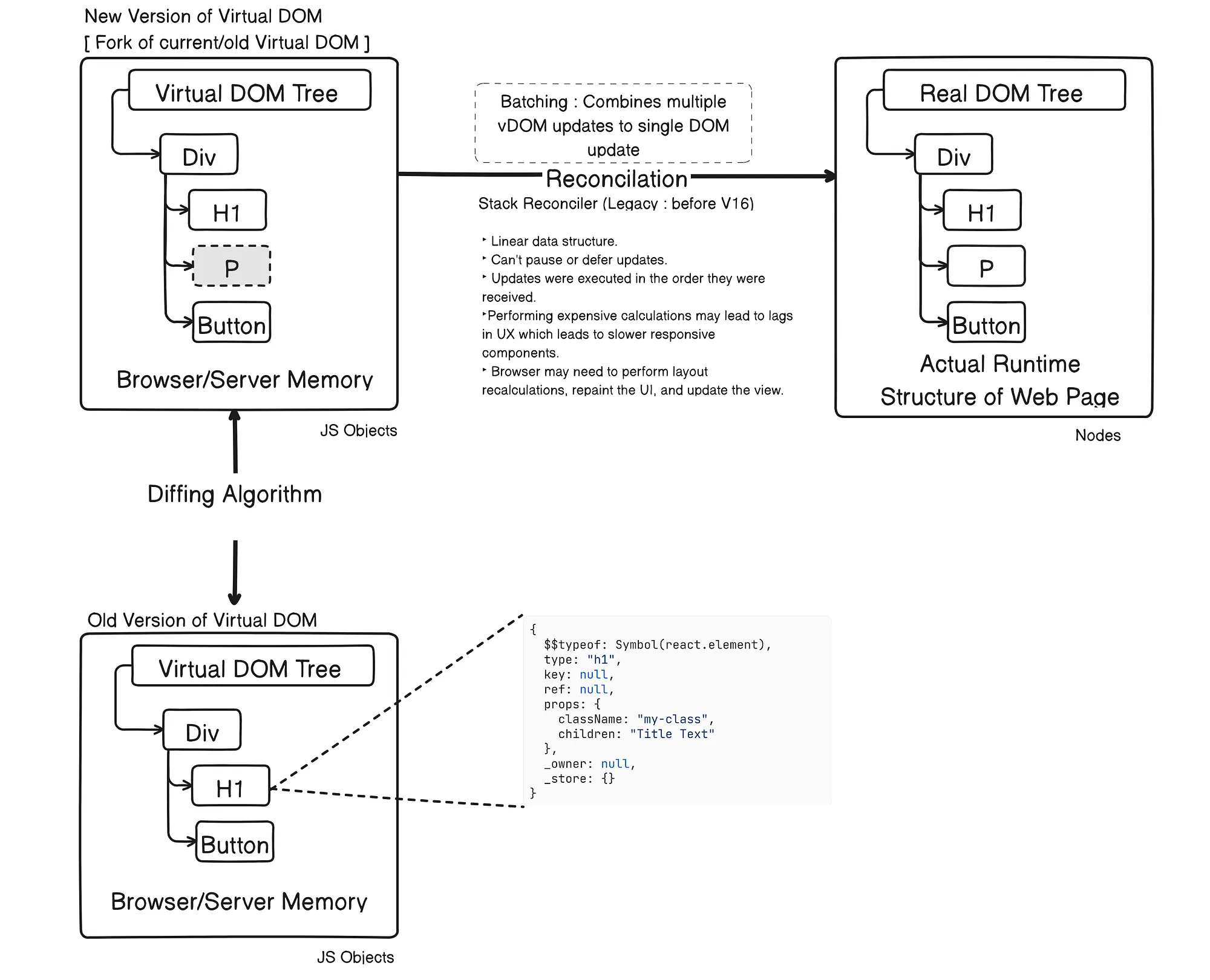
React then uses a diffing algorithm to compare the current version of the Virtual DOM with the previous version. This process identifies the differences (or "diffs") between the two versions.
Based on the differences identified, React determines the most efficient way to update the real DOM. Only the parts of the real DOM that need to be updated are changed, rather than re-rendering the entire UI. This selective updating is quick and performant and the whole process of diffing and calculating optimal updates is known as Reconciliation. React then applies all the calculated changes to the DOM in one synchronous sequence.
Phases
The whole process of rendering is divided into two main phases —
- The Render Phase contains all the processes for compiling components and calculating changes.
- The Commit Phase involves the process of applying those changes to the actual DOM.
After react has updated the DOM in the commit phase, it updates all refs accordingly to point to the requested DOM nodes and component instances. It then synchronously runs
componentDidMount&componentDidUpdatefor class components anduseLayoutEffecthook for the functional components. React then sets a short timeout, and when it expires, runs all theuseEffecthooks. This step is also known as Passive Effects phase.
Asynchronous Rendering
React 16 added concurrent rendering features like React Fiber engine & hooks like
useTransition, useSyncExternalStore etc. This gives React the ability to pause the work on rendering phase to allow the browser to process events. React will either resume, throw away or recalculate that work later as appropriate. Once the render phase is
complete, React will run the commit phase synchronously in one step.See React Fiber section.
Refer to following for more details —
After the initial render process is complete, there are a few different ways to queue a re-render process -
- Functional Components
useStatesettersuseReducersetters
- Class Components
this.setState()this.forceUpdate()
For more details about different hooks and lifecycle methods, refer to [[React — Lifecycle]]
Behaviour & Rules
React's default behaviour is that when a parent component renders, React will recursively render all child components inside it. React does not care whether the props changed - it will render all the child components unconditionally just because the parent component rendered.
One of the primary rules of React rendering is that rendering must be pure, and not have any side effects. In React, pure mostly means, idempotent - it will always return the same thing for the same input.
In other words, render logic must not -
- Mutate or read existing variable bindings, unless they were newly created
- Mutate or read object properties, unless they were newly created
- Mutate a property on
thisexcept the constructor - Create random values like
Math.random()orDate.now() - Make network requests
- Queue state updates
- Create new components.
- Call another function that might perform any of the above actions.
Newly created means that the object, or the closure around a variable binding, was created inside the pure function call itself. Note that it is not enough that the variable or object was created by some previous invocation of this function. It has to be created within that function execution context.
React Fiber
The React "Fiber" reconciler, which became the default reconciler for React@16 and above, is an overhaul of React's original "Stack" reconciler. The core idea behind fiber is to enable React to take advantage of concurrency and scheduling by -
- Assigning priority to different types of work - an animation update needs to complete more quickly than, say, an update from data store.
- Pause work and come back to it later. In a UI, it is not necessary for every update to be applied immediately; in fact, doing so can be wasteful, causing frames to drop and thereby degrading the user experience.
- Abort work if it's no longer needed.
- Reuse previously completed work.
Before Fiber (< React@16)
Rendering a React app is akin to calling a function which contains calls to other functions, and so on. A program's execution is typically tracked using call stack. When a function is executed, a new stack frame is added to the call stack. A stack frame represents the work that is being performed by that function.
When dealing with UIs, the problems is that if too much work is executed all at once (call stack is loaded with stack frames), it can cause UI updates or animations to drop frames and feel choppy. Some of that work may even be unnecessary if it's superseded by some recent update. Newer browsers implement APIs that help address this problem -
requestIdleCallback schedules a low priority functions to be called during an idle period, and requestAnimationFrame schedules a high priority function to be called on the next animation frame.The React "Stack" Reconciler refers to the reconciliation algorithm used in React versions prior to React 16. It's primary function was to determine the minimal changes needed to update the actual DOM when a component's state or props changed. It operated as a single, uninterrupted process, traversing the Virtual DOM tree recursively using the JavaScript call stack. Once reconciliation began, it continued until the entire tree was processed, regardless of other tasks or user interactions. The reconciler would explore the component tree in a depth-first manner, processing each node and its children before moving to the next sibling. Due to its synchronous nature, the Stack Reconciler could block the main thread for extended periods, especially in large applications with complex component trees. This could lead to a less responsive user experience, as high-priority updates like user input or animations might be delayed.
After Fiber (>= React@16)
React Fiber is a complete overhaul of React's reconciliation algorithm. The goal is to increase React's suitability for areas like animations, layouts and gestures. It's headline feature is incremental rendering - the ability to split rendering work into chunks (fibers) and spread it over multiple frames. Other key features include the ability to pause, abort, or reuse work as new updates come in; the ability to assign priority to different types of updates; and new concurrency primitives that enable features like Suspense and Concurrent mode.
React stores an internal data structure that tracks all the current component instances that exist in the application. The core piece of this data structure is an object called a "Fiber", which contains metadata fields that describe -
- Component type
- Current props and state associated with this component
- Pointers to parent, sibling, and child components
- Other internal metadata that React uses to track the rendering process.
Definition of React Fiber type (as of React 18) - React Fiber Type
// A Fiber is work on a Component that needs to be done or was done. There can
// be more than one per component.
export type Fiber = {|
// These first fields are conceptually members of an Instance. This used to
// be split into a separate type and intersected with the other Fiber fields,
// but until Flow fixes its intersection bugs, we've merged them into a
// single type.
// An Instance is shared between all versions of a component. We can easily
// break this out into a separate object to avoid copying so much to the
// alternate versions of the tree. We put this on a single object for now to
// minimize the number of objects created during the initial render.
// Tag identifying the type of fiber.
tag: WorkTag,
// Unique identifier of this child.
key: null | string,
// The value of element.type which is used to preserve the identity during
// reconciliation of this child.
elementType: any,
// The resolved function/class/ associated with this fiber.
type: any,
// The local state associated with this fiber.
stateNode: any,
// Conceptual aliases
// parent : Instance -> return The parent happens to be the same as the
// return fiber since we've merged the fiber and instance.
// Remaining fields belong to Fiber
// The Fiber to return to after finishing processing this one.
// This is effectively the parent, but there can be multiple parents (two)
// so this is only the parent of the thing we're currently processing.
// It is conceptually the same as the return address of a stack frame.
return: Fiber | null,
// Singly Linked List Tree Structure.
child: Fiber | null,
sibling: Fiber | null,
index: number,
// The ref last used to attach this node.
// I'll avoid adding an owner field for prod and model that as functions.
ref:
| null
| (((handle: mixed) => void) & {_stringRef: ?string, ...})
| RefObject,
// Input is the data coming into process this fiber. Arguments. Props.
pendingProps: any, // This type will be more specific once we overload the tag.
memoizedProps: any, // The props used to create the output.
// A queue of state updates and callbacks.
updateQueue: mixed,
// The state used to create the output
memoizedState: any,
// Dependencies (contexts, events) for this fiber, if it has any
dependencies: Dependencies | null,
// Bitfield that describes properties about the fiber and its subtree. E.g.
// the ConcurrentMode flag indicates whether the subtree should be async-by-
// default. When a fiber is created, it inherits the mode of its
// parent. Additional flags can be set at creation time, but after that the
// value should remain unchanged throughout the fiber's lifetime, particularly
// before its child fibers are created.
mode: TypeOfMode,
// Effect
flags: Flags,
subtreeFlags: Flags,
deletions: Array<Fiber> | null,
// Singly linked list fast path to the next fiber with side-effects.
nextEffect: Fiber | null,
// The first and last fiber with side-effect within this subtree. This allows
// us to reuse a slice of the linked list when we reuse the work done within
// this fiber.
firstEffect: Fiber | null,
lastEffect: Fiber | null,
lanes: Lanes,
childLanes: Lanes,
// This is a pooled version of a Fiber. Every fiber that gets updated will
// eventually have a pair. There are cases when we can clean up pairs to save
// memory if we need to.
alternate: Fiber | null,
// Time spent rendering this Fiber and its descendants for the current update.
// This tells us how well the tree makes use of sCU for memoization.
// It is reset to 0 each time we render and only updated when we don't bailout.
// This field is only set when the enableProfilerTimer flag is enabled.
actualDuration?: number,
// If the Fiber is currently active in the "render" phase,
// This marks the time at which the work began.
// This field is only set when the enableProfilerTimer flag is enabled.
actualStartTime?: number,
// Duration of the most recent render time for this Fiber.
// This value is not updated when we bailout for memoization purposes.
// This field is only set when the enableProfilerTimer flag is enabled.
selfBaseDuration?: number,
// Sum of base times for all descendants of this Fiber.
// This value bubbles up during the "complete" phase.
// This field is only set when the enableProfilerTimer flag is enabled.
treeBaseDuration?: number,
// Conceptual aliases
// workInProgress : Fiber -> alternate The alternate used for reuse happens
// to be the same as work in progress.
// __DEV__ only
_debugSource?: Source | null,
_debugOwner?: Fiber | null,
_debugIsCurrentlyTiming?: boolean,
_debugNeedsRemount?: boolean,
// Used to verify that the order of hooks does not change between renders.
_debugHookTypes?: Array<HookType> | null,
|};
During rendering pass, React will iterate over this tree of fiber objects, and construct an updated tree as it calculates the new rendering results.
These "fiber" objects store the real component props and state values. When using props and state in components, React is actually providing direct access to the values that were stored on the fiber objects. Similarily, React hooks work because React stores all of the hooks for a component as a linked list attached to that component's fiber object. When React renders a function component, it gets that linked list of hook description entries from the fiber, and every time another hook is called, it returns the appropriate values that were stored in the hook description object (like the state and dispatch values for useReducer.
Refer to this piece of code - React Fiber Memoized Hooks
When a parent component renders a given child component for the first time, React creates a fiber object to track that "instance" of a component. For class components, it literally calls and saves the actual component instance onto the fiber object.
const instance = new YourComponentType(props)
Reconciliation
React tries to be efficient during re-renders, by reusing as much of the existing components tree and DOM structure as possible. Instead of re-creating components from scratch, React re-uses components of the same type and just applies appropriate updates.
React's rendering logic compares elements based on the following criteria -
- Type Field — React's rendering logic compares elements based on their
typefield first, using===reference comparisons. If an element in a given spot has changed to a different type, such as going from<div>to<span>or<ComponentA>to<ComponentB>, React will speed up the comparison process by assuming that entire tree has changed. As a result, React will destroy that entire existing component tree section, including all DOM nodes, and recreate it from scratch with new component instances.
This means that you must never create new component types while rendering! Whenever you create a new component type, it's a different reference, and that will cause React to repeatedly destroy and recreate the child component tree.
- Key Prop — The other way that React identifies component "instances" is via the
keypseudo-prop. React useskeyas a unique identifier that it can use to differentiate specific instances of a component type. The main place we use keys is rendering lists. Keys are especially important here if you are rendering data that may be changed in some way, such as reordering, adding, or deleting list entries. It's particularly important here that keys should be some kind of unique IDs from your data if at all possible - only use array indices as keys as a last resort fallback!
// ✅ Use a data object ID as the key for list items
todos.map((todo) => <TodoListItem key={todo.id} todo={todo} />);
The
key isn't actually a real prop - it's an instruction to React. React will always strip that off, and it will never be passed through to the actual component, so you can never have props.key - it will always be undefined. A key prop can be added to any React component at any time to indicate its identity, and changing that key will cause React to destroy the old component instance and DOM and create new ones.Render Batching & Async Rendering
By default the
setState() causes React to start a new render pass, execute it synchronously (the commit phase) and return. However, react also applies some optimisations automatically, in the form of render batching. Render batching is when multiple setState() calls are batched together resulting in a single render and commit phase, usually with a slight delay. By waiting until the current JavaScript event-loop turn finishes and then applying every queued state change in one go, React trades a tiny delay for a big reduction in duplicated work.Before React 17, react only performed automatic render batching for event handler functions such as
onClick() callbacks. Updates queued outside of event handlers such as setTimeout or await were not batched and would result in separate re-renders. However, since React 18, automatic render batching is performed for all updates queued in any single event loop tick — unless explicitly opted out with flushSync(). This helps cut down the number of re-renders needed.Consider the following code snippet —
const [counter, setCounter] = useState(0);
const onClick = async () => {
setCounter(0);
setCounter(1);
const data = await fetchSomeData();
setCounter(2);
setCounter(3);
};
In React 17 this logs three renders – one for the first two setters, then one each for
2 and 3. Synchronous updates in the same event handler are batched (1st render). Each async update after an await or timer is treated as a separate render (2nd and 3rd renders).In React 18 it logs two renders – one for
0 → 1, one for 2 → 3. The core idea is: if multiple state updates happen close together — whether synchronously or asynchronously — they likely represent a single logical change in the UI. This change reflects a broader philosophy: treat the entire event loop tick as a single “transaction,” regardless of whether updates are triggered by user events, timers, or async operations.Refer to this PR — Automatic batching for fewer renders in React 18
The above behaviour is often described using the following saying — "state updates may be asynchronous". This is sort of true though, but there are more things at work here. For example,
function MyComponent() {
const [counter, setCounter] = useState(0);
const handleClick = () => {
setCounter(counter + 1);
// ❌ THIS WON'T WORK!
console.log(counter);
// Original value was logged - why is this not updated yet??????
};
}
Even though the react render is synchronous, however, from the point of view of that
handleClick() function, it's "async" in that the results cannot be immediately seen, and the actual update occurs much later than the setCounter() call. But, there is a bigger reason. The handleClick() function is a "closure" - it can only see the values of variables as they existed when the function was defined. In other words, these state variables are a snapshot in time.Since
handleClick() was defined during the most recent render of the MyComponent function component, React can only see the value of counter as it existed during that render pass. When the setCounter() is called, React queues up a future render pass, and that future render will have a new counter variable with the new value and a new handleClick function; but this copy of handleClick will never be able to see that new value.This is also described in the following React documentation — State as a snapshot
Server-Side Rendering (SSR)
Server-side rendering (SSR) is a technique where the HTML of a web page is generated on the server and sent to the client. This allows for faster initial page loads and better SEO since the content is already available when the page is loaded.
Hydration
Hydration is the process that happens after the server-side rendered HTML is sent to the client. React takes the static HTML and "hydrates" it by attaching event listeners and initialising the state, making the page interactive.
- Reusing the existing HTML: React uses the HTML generated by the server and does not re-render it from scratch.
- Attaching event listeners: React attaches the necessary event listeners to the existing HTML elements.
- Initialising state: React initialises the component state and props to make the page dynamic.
For example,
- Server-side rendering: The server generates the following HTML —
<div id="root">
<button>Click me</button>
</div>
- Client-side hydration: When the HTML is sent to the client, React hydrates it with the following code —
import React from 'react';
import ReactDOM from 'react-dom';
function App() {
const handleClick = () => {
alert('Button clicked!');
};
return <button onClick={handleClick}>Click me</button>;
}
ReactDOM.hydrate(<App />, document.getElementById('root'));
References
- https://react.dev/
- https://blog.isquaredsoftware.com/
- https://pomb.us/build-your-own-react/
- https://www.zhenghao.io/posts/react-rerender
- https://overreacted.io/a-complete-guide-to-useeffect/
- https://www.alibabacloud.com/blog/a-closer-look-at-react-fiber_598138
- https://blog.kiprosh.com/react-fiber/
- https://medium.com/desired-software-dev/react-stack-reconciliation-8a88780c489f
- https://julesblom.com/writing/react-hook-component-timeline
- https://www.greatfrontend.com/questions/quiz/explain-what-react-hydration-is
- https://www.joshwcomeau.com/react/server-components/